



Introduction
In today’s digital age, feedback is crucial for service-based industries, especially hospitality. Hotel reviews shared on platforms like TripAdvisor, Expedia, and Google Reviews offer valuable insights into customer experiences. These reviews contain important sentiment data, helping hotels understand guest sentiments and identify the strengths and weaknesses of their service.
In this guide, we will share the process of how to turn datasets containing the text of hotel reviews and other information and turn them into useful business insight using a pre-trained model, BERT, and Python.
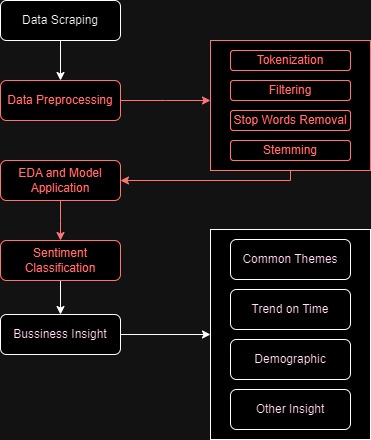
We'll explore the power of Customer Sentiment Analysis using Python to understand customer feedback better.
The Importance of Sentiment Analysis
As we are currently standing in the era of machine learning, deep learning, and AI, we can bring data analysis further. We are stepping into understanding not only quantity data but also qualitative data such as text data that usually can be represented in words only. However, using a part of deep learning called Natural Language Processing (NLP), we can understand these texts more deeply.
Using Natural Language Processing (NLP), we can analyze text data to distinguish the positive and negative connotations it conveys. We call this process "Customer Sentiment Analysis," which falls under the broader domain of sentiment analysis.
Sentiment analysis is a branch of NLP that focuses on identifying and categorizing a piece of text based on the emotional tone. We can categorize it into positive connotations and negative connotations.
Sentiment analysis is a branch of NLP that focuses on identifying and categorizing a piece of text based on the emotional tone. We can categorize it into positive and negative connotations. This technique helps businesses understand customer emotions and sentiments from textual feedback, providing valuable insights for improving service and customer satisfaction.
Sentiment analysis is a powerful tool that enables organizations to understand the emotions and opinions expressed in various forms of text data. By analyzing customer reviews, social media posts, and other textual data, businesses can gain valuable insights into customer satisfaction and preferences. This technology has applications across numerous industries, including retail, finance, healthcare, and, notably, hospitality.
Customer Sentiment Analysis utilizes natural language processing (NLP) and machine learning algorithms to classify the sentiment expressed in a text as positive, negative, or neutral. Advanced models can even detect specific emotions like joy, anger, or sadness. By aggregating these sentiments, companies can track trends and make informed decisions. Understanding how Customer Sentiment Analysis can be used to improve customer experience is key to tailoring customer service strategies effectively.
These are application of Customer Sentiment Analysis in various industries.
- Retail: Retailers use Customer Sentiment Analysis to monitor customer feedback on products and services, enabling them to adjust their offerings and marketing strategies accordingly.
- Finance: Financial institutions apply Customer Sentiment Analysis to gauge public opinion about market trends, company performance, and economic conditions, which can influence trading decisions and risk management.
- Healthcare: In healthcare, Customer Sentiment Analysis helps in understanding patient feedback, improving patient care, and monitoring the public's response to health policies and campaigns.
- Entertainment: Customer Sentiment Analysis is used to measure audience reactions to movies, TV shows, and music, helping creators and producers tailor content to audience preferences.’
In the hospitality industry, Customer Sentiment Analysis has become an essential tool for enhancing customer experience and maintaining a competitive edge. Here are some specific applications:
- Reviews and Ratings: By analyzing online reviews and ratings on platforms like TripAdvisor, Booking.com, and Google Reviews, hotels can identify common praises and complaints. This allows them to address issues promptly and improve service quality. Customer Sentiment Analysis using hotel review data is a powerful method for understanding the overall customer experience in the hospitality industry.
- Social Media Monitoring: Monitoring social media platforms for mentions and discussions about their brand helps hotels understand customer sentiment in real-time and respond to feedback quickly.
- Identifying Main Points: Customer Sentiment Analysis can highlight recurring issues such as cleanliness, staff behavior, or amenities, enabling hotels to take corrective actions.
- Enhancing Guest Experience: By recognizing what guests appreciate the most, hotels can focus on enhancing those aspects of their service, such as personalized greetings, room upgrades, or special amenities.
What is Customer Sentiment Analysis?
Customer Sentiment Analysis, also known as opinion mining, is a branch of natural language processing (NLP) that involves identifying and categorizing opinions expressed in text data to determine the writer’s attitude toward a particular topic. This attitude can be classified as positive, negative, or neutral, and advanced models can even detect specific emotions such as joy, anger, or sadness.
Customer Sentiment Analysis uses machine learning algorithms and NLP techniques to analyze text data from various sources, such as social media, reviews, and customer feedback. By examining the contextual meaning of words and phrases, Customer Sentiment Analysis tools can assess the overall sentiment and extract valuable insights from large volumes of text.
These are types of Customer Sentiment Analysis:
- Polarity Detection: The most common type, where sentiments are classified as positive, negative, or neutral.
- Emotion Detection: This involves identifying specific emotions expressed in the text, such as happiness, sadness, anger, or surprise.
- Aspect-Based Sentiment Analysis: This type focuses on identifying the sentiment towards specific aspects or features of a product or service. For example, in hotel reviews, aspects could include cleanliness, service, or location.
- Multilingual Sentiment Analysis: This involves analyzing sentiment expressed in multiple languages, which is particularly useful for global businesses.
 Shannon Torcato
Shannon Torcato
Impact of Customer Sentiment Analysis on Hotel Performance
Customer Sentiment Analysis has a significant impact on the performance of hotels. By leveraging this technology, hotels can gain a deeper understanding of customer perceptions and make data-driven decisions to enhance their operations.
- Enhancing Customer Experience
Personalized Services: By analyzing guest feedback, hotels can identify individual preferences and tailor services to meet specific needs, resulting in a more personalized and satisfying experience.
Real-Time Feedback: Monitoring social media and reviewing sites in real-time allows hotels to address guest concerns promptly, improving guest satisfaction and loyalty. - Improving Service Quality
Identifying Main Points: Customer Sentiment Analysis helps hotels identify recurring issues such as problems with cleanliness, staff behavior, or amenities. Addressing these issues can lead to significant improvements in service quality.
Benchmarking Performance: By comparing sentiment scores with competitors, hotels can benchmark their performance and implement best practices to enhance their services. - Strategic Decision Making
Targeted Marketing Campaigns: Insights from Customer Sentiment Analysis can guide marketing strategies. For instance, if guests frequently praise a hotel’s spa services, the hotel can focus its marketing efforts on promoting spa packages and special offers.
Product and Service Development: Understanding customer sentiment helps hotels make informed decisions about new services or amenities to introduce, ensuring they align with guest preferences and demand.
Reputation Management: Proactively managing online reputation by responding to feedback and promoting positive experiences helps build a strong brand image, attracting more guests.
Getting Started with Sentiment Analysis
Identifying Tools in Python
The tools we are going to use are as follows.
- Python is the programming language. For the environment, we are going to use Google Colab, so we can apply Google Drive as our file directory.
- google.colab, this library is used for accessing files from Google drive
- Collections.Counter: this library is used to count iterable objects, used for frequency analysis.
- pandas: this library is used for data manipulation and analysis library using data frames on our datasets.
- numpy: this library used for numerical operation.
- matplotlib: this library is used to create plots and charts.
- re: this library is used for regular expressions, which are used for searching, matching, and manipulating text.
- nltk: This library is used for natural language processing, specifically exploratory data analysis, and models are applied to our datasets.
- transformers - pipeline: this library is used as a model that we can use for Customer Sentiment Analysis on our datasets.
- wordcloud: this library is used to generate word clouds, which are usually used to represent frequency words in a text dataset.
- vaderSentiment - SentimentIntensityAnalyzer: this library is used to provide a sentiment score for a given text, indicating whether a given text is considered a positive or negative connotation.
With Customer Sentiment Analysis tools in Python, you can efficiently process large datasets of customer reviews and extract valuable insights.
Now that we already see the library we are going to use, we are going to get an overlook on our datasets.
DataHen
Explanation of Fundamental, Deep Learning, and Visualization Library
In this guide, we are dividing our tools into three different groups.
- Fundamental Libraries
In the realm of fundamental libraries for data manipulation and processing, several tools are indispensable. NumPy is a cornerstone library in Python that provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently. Google Colab offers a cloud-based environment for running Python code and is especially popular for its seamless integration with Google Drive, making it an excellent tool for collaborative coding and data analysis. Collections - Counter is a specialized data structure within Python’s collections module that is used for counting hashable objects, providing an efficient way to tally occurrences of elements. Lastly, re is Python's built-in module for regular expressions, which allows for powerful text searching and manipulation, making it essential for text-processing tasks. - Visualization Libraries
Visualization libraries are crucial for interpreting and presenting data insights effectively. WordCloud is a library used to generate visually appealing word clouds that highlight the frequency of words in a textual dataset, providing an intuitive way to visualize word prominence. Matplotlib is a widely used plotting library in Python that offers a versatile range of plotting capabilities, enabling the creation of static, animated, and interactive visualizations. On top of Matplotlib, Seaborn enhances data visualization by providing a high-level interface for drawing attractive and informative statistical graphics, incorporating features such as built-in themes and color palettes that streamline the creation of complex plots. - Deep Learning Libraries
Natural Language Processing (NLP) is a field of AI focused on the interaction between computers and human languages. It involves enabling computers to understand, interpret, and generate human language in a way that is both meaningful and useful. NLP combines computational linguistics with machine learning and deep learning to process and analyze large amounts of natural language data. As part of NLP, we have a chunk of models called Large Language Model or LLM.
Large Language Models (LLMs) are advanced models trained on vast amounts of text data to understand and generate human language. These models, such as GPT-3 and GPT-4, can perform a wide range of NLP tasks. In Customer Sentiment Analysis, LLMs can provide a nuanced understanding and classification of sentiments in hotel reviews, even when the language is complex or the sentiment is subtle.
BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained NLP model developed by Google that uses the Transformer architecture. It is designed to understand the context of a word in search queries by looking at the words that come before and after it. This bidirectional approach allows BERT to have a deeper understanding of language context and nuance. Unlike traditional models that read text sequentially, BERT reads text in both directions (left-to-right and right-to-left), allowing it to understand the full context of a word.
NLTK (Natural Language Toolkit) provides a comprehensive suite of tools for processing and analyzing human language data, including resources for text classification, tokenization, and linguistic data analysis. Transformers by Hugging Face offers state-of-the-art pre-trained models for various NLP tasks, such as text classification and Customer Sentiment Analysis, making it easier to leverage powerful language models in applications. VADER
SentimentIntensityAnalyzer is a tool within the VADER Customer Sentiment Analysis library that delivers a simple yet effective way to determine the sentiment of text, using a lexicon and rule-based approach to evaluate sentiment intensity in a nuanced manner.
Shannon Torcato
Overview on Datasets
To begin with the Customer Sentiment Analysis, let’s check our datasets first. The raw datasets we are going to use are hotel data, including the hotel review from Google Review from Early May 2024 to Early July 2024. By utilizing web scraping, we can extract datasets with the current format.
- extracted_on: The date the hotel review scraped on
- name: name of the hotel
- source: The source website of the hotel review
- hotel_key: a string that indicates a specific hotel
- overall_rating: the overall rating of the hotel
- generated_review_id: a unique code that indicates a specific hotel review
- rating: the rating that the user gave regarding the hotel experience
- trip_type: the type of trip the user takes
- date_of_review: the date of the user's hotel review
- approximate_time_since_review: approximate time between the hotel review and the scraping happened
- original_review_text: the review the user gave in any language
- translated_review_text: the review user gave in the English language
- original_hotel_response: the response the hotel gives about the user review in the respective language
- translated_hotel_response: the response the hotel gives about the user review in the English language
- url: the URL link to the user review
Now, let’s check step-on-step analysis on how to do Customer Sentiment Analysis and extract business insights from it.
Shannon Torcato
Step-by-Step with Sentiment Analysis
Basic Preparation
First, let’s do a basic preparation. The first step is to import the library we are going to use in the analysis.
from google.colab import drive
from collections import Counter
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from transformers import pipeline
from wordcloud import WordCloud
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzerThe next step is to upload them to Google Drive. By creating a Google Colab notebook, we apply the Google Drive mount function to access our files directly from Google Drive. This allows us to read the datasets easily in our environment.
To ensure everything is correctly loaded, we create a preview of the dataset. This involves printing the headers and the first five rows of the data, confirming that the datasets have been imported correctly and are ready for further analysis.
#Locate the file path
file_path = '/content/drive/MyDrive/Link to The File in Drive'
#Read the file into a DataFrame
df = pd.read_excel(file_path)
# Display the first few rows of the DataFrame
display(df)
Below is the XML preview for Hotel Z.
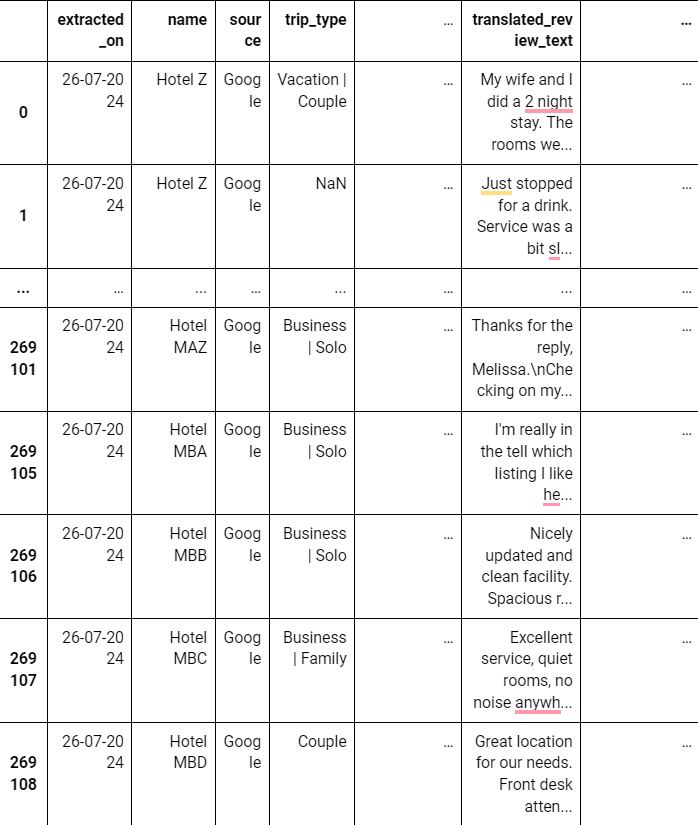
Now that we already have the dataFrame of the datasets, let’s preprocess it.
Let’s clean the data first. We will only use name, overall_rating, rating, trip_type, date_of_review, original_review_text, and translated_review_text.
Notice that we need the review in the English language. Not every review is in English, and we need to translate it later. If the review is already in English, then the translated_review_text in the same row is empty. So, to reduce the column, we want to put the original_text_review to translated_text_review if the translated_text_review is empty. And we delete the original_text_review column.
#Select the desired columns
desired_columns = ['name', 'overall_rating' 'rating','trip_type','date_of_review', 'original_review_text', 'translated_review_text']
new_df = df[desired_columns]
#Fill empty translated_review_text with original_review_text
new_df['translated_review_text'] = new_df.apply(
lambda row: row['original_review_text'] if pd.isna(row['translated_review_text']) else row['translated_review_text'], axis=1)
#Delete original_review_text column
new_df = new_df.drop(columns=['original_review_text'])
#Check empty 'translated_review_text' rows
empty_rows = new_df[new_df['translated_review_text'].isnull() | (new_df['translated_review_text'] == '')]
new_df.dropna(subset=['translated_review_text'], inplace=True)
We create a new XML file only by using these columns and save it to Google Drive. Then, we overwrite the current dataFrame with this new XML file.
Now that we already have a clean XML, we want to create a new column, that is cleaned_review. This column was created by standardizing translated_review_text. These are the steps to create it, we call it Text Preprocessing. Text Preprocessing is divided into a few steps.
- Tokenization: Split text into individual words or tokens.
- Lowercasing: Convert all text to lowercase to maintain consistency.
- Removing stopwords: Eliminate common words (e.g., "and", and "the") that don't contribute much to sentiment.
- Lemmatization/Stemming: Reduce words to their base or root form.The final product of these steps is a list of words based on the review, in a base form. We will utilize this list for further analysis.
# Initialize lemmatizer and stopwords list
lemmatizer = WordNetLemmatizer()
stop_words = set(stopwords.words('english'))
# Function to preprocess text
def preprocess_text(text):
# Lowercase the text
text = text.lower()
# Remove non-alphabetic characters
text = re.sub(r'[^a-z\s]', '', text)
# Tokenize the text
words = text.split()
# Remove stopwords and lemmatize
words = [lemmatizer.lemmatize(word) for word in words if word not in stop_words]
return ' '.join(words)
# Apply preprocessing to the translated_review_text column
new_df['cleaned_review'] = new_df['translated_review_text'].apply(preprocess_text)
# Display the first few rows to verify
print(new_df[['translated_review_text', 'cleaned_review']].head())The new_df data frame would have a preview like this. For simplicity, let’s check Hotel Z here.
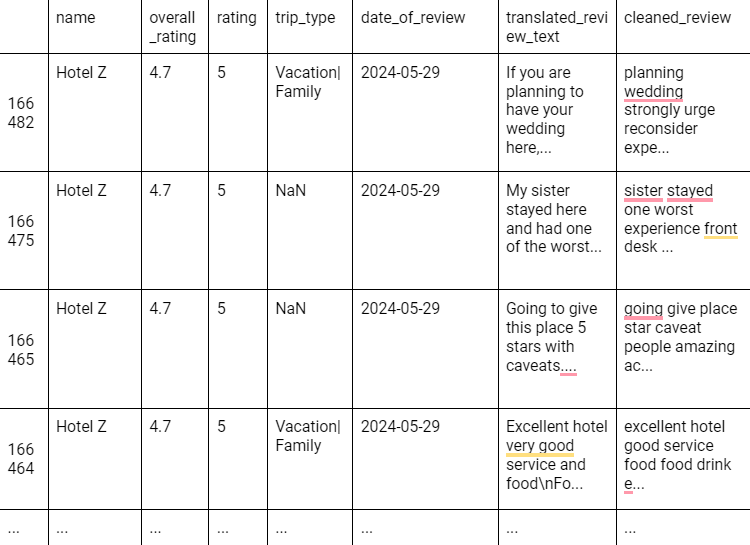
Now let’s check a few properties from this dataframe and apply sentiment to it.
Shannon Torcato
Applying BERT Model
Now we want to apply the BERT model to our text review. We can use this piece of code to run it.
nlp = pipeline("sentiment-analysis")
# Predict sentiments
reviews = new_df['translated_review_text'].tolist()
results = nlp(reviews, truncation=True)
# Extract sentiment labels and scores
new_df['sentiment_new'] = [result['label'] for result in results]
new_df['score_new'] = [result['score'] for result in results]This piece of code would apply the BERT Model to text and will decide if the text review has positive or negative connotations. It will give two outputs, the label to decide if the text review has a positive connotation or negative connotation, and the score that denotes the percentage of the probability of a given connotation. We create new two columns that denote the label and the score.
The transformers library by Hugging Face is a popular Python library for natural language processing (NLP). It provides pre-trained models and tools for various NLP tasks, such as text classification, translation, and question-answering. The pipeline function in the transformers library is a high-level API that simplifies the use of pre-trained models for specific NLP tasks. It abstracts away much of the complexity involved in setting up and using these models.
The argument "sentiment-analysis" specifies the type of task for which you want to create a pipeline. In this case, it’s sentiment analysis, which involves determining the sentiment expressed in a piece of text. The pipeline function will automatically handle:
- Model Selection: It selects a pre-trained model suitable for Customer Sentiment Analysis from its model hub.
- Tokenization: It tokenizes the input text, converting it into a format that the model can process.
- Model Inference: It runs the tokenized input through the model to generate predictions.
- Post-Processing: It decodes the model’s output into a human-readable format, such as sentiment labels and scores.
The pipeline also loads a pre-trained model from the Hugging Face model hub that is fine-tuned for Customer Sentiment Analysis. The final product will give us the sentiment for each review, either positive or negative, along with the probability on a scale of 0 to 1. Here is the example for the new dataset on Hotel Z.
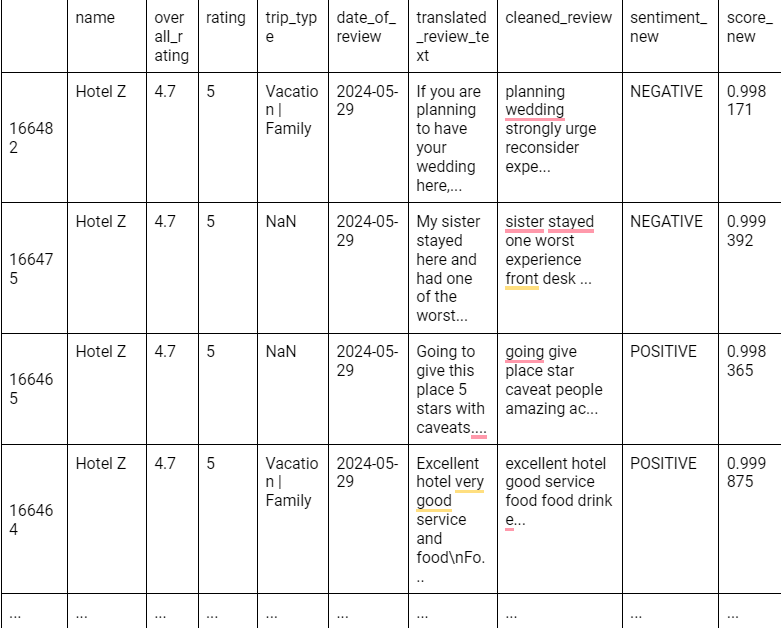
BERT sentiment analysis offers a more nuanced understanding of customer opinions by leveraging advanced natural language processing techniques. Using BERT sentiment analysis, businesses can accurately detect the sentiment behind complex customer feedback. We will see an application of this BERT sentiment analysis for business insight.
After the process, we have with Python, we can do several steps to gain business insight. Many businesses wonder, how can sentiment analysis be used to improve customer experience. By analyzing feedback, companies can pinpoint the main points and enhance their services. These are a few business insights that we can generate.
- Common Themes in Hotel Reviews - Positive and Negative Reviews
To uncover common themes in hotel reviews, both positive and negative, visualizations can be highly effective. Utilizing Seaborn and Matplotlib, one can generate word clouds to visually represent frequently mentioned terms and phrases in reviews. For positive reviews, the word cloud might prominently feature words like "friendly," "clean," or "comfortable," whereas negative reviews might highlight issues such as "noisy," "uncomfortable," or "unresponsive." By analyzing these word clouds, it's possible to discern key strengths and areas for improvement as perceived by customers, providing actionable insights into what aspects of the hotel are resonating well or causing dissatisfaction. - Trends in Hotel Reviews Over Time
Tracking trends in hotel reviews over time helps to understand how customer sentiment evolves. Using Matplotlib, one can create line charts or time series plots to visualize changes in average ratings or review frequencies across different time intervals. For example, plotting monthly average ratings can reveal whether recent renovations or changes in management have positively or negatively impacted customer satisfaction. - Demographics of Our Reviewers
Understanding the demographics of reviewers provides valuable context for interpreting feedback. Seaborn can generate demographic distribution plots such as histograms in trip type or age, based on available data. - Various Customer Segments
Segmenting customers into different categories allows for a more nuanced analysis of reviews. Using Matplotlib, one can create bar charts or pie charts to visualize the distribution of reviews across various customer segments, such as business travelers, families, or solo tourists. - Customer Reviews Regarding Price and Value
Evaluating customer reviews in relation to price and value provides insight into how guests perceive the cost versus their overall experience. Matplotlib can complement this with bar charts showing average ratings segmented by price ranges, illustrating if guests feel they are getting their money’s worth. Analyzing these visualizations can help in adjusting pricing strategies or enhancing value propositions to better meet customer expectations.
You can check our business insight article here.
Lanang Bagaskara
Challenges and Solution
- Different Languages on Hotel Review Text
Sentiment analysis models often struggle with multilingual texts. Hotel reviews might be written in various languages, which can complicate the analysis as different languages have distinct syntactic and semantic structures.
To address this, one can use multilingual or cross-lingual models like XLM-R (Cross-lingual Language Model - RoBERTa) or mBERT (Multilanguage BERT) that are trained on multiple languages. Additionally, employing translation services to convert all reviews to a single language before analysis can also be effective. Ensuring your dataset is diverse and representative of the languages you expect can improve model robustness. - Sarcasm on Hotel Review Text
Detecting sarcasm is particularly difficult for sentiment analysis models because the literal meaning of the words used can be the opposite of the intended sentiment. For example, a review stating, "Great! Another sleepless night thanks to the noisy neighbors” is clearly a negative despite the positive wording.
To mitigate this, incorporating context-aware models such as BERT (Bidirectional Encoder Representations from Transformers) can help, as they consider the context of the words in a sentence. Additionally, sentiment analysis can be improved by training models on annotated datasets specifically labeled for sarcasm. Using feature engineering techniques to detect indicators of sarcasm (e.g., using exclamation marks, and certain adjectives in a negative context) can also enhance model performance. - Low Accuracy on Hotel Review Text using BERT
BERT models, despite being state-of-the-art, might not always achieve high accuracy on specific tasks like sentiment analysis of hotel reviews due to domain-specific language, limited training data, or sub-optimal hyper parameters.
Fine-tuning BERT on a domain-specific dataset can significantly improve performance. Gathering a substantial amount of labeled hotel review data and augmenting the dataset through techniques like data augmentation can help. Furthermore, optimizing hyper parameters through cross-validations and experimenting with different configurations (e.g., learning rate, batch size) can lead to better results. Incorporating additional features such as metadata (e.g., review rating, length of stay) can provide more context to the model. - Not enough Hotel Review Text
A lack of sufficient data can hinder the performance of sentiment analysis models, as they rely heavily on large datasets to learn and generalize effectively.
Data augmentation techniques, such as paraphrasing, back-translation, or synthetic data generation, can be used to expand the dataset. Leveraging transfer learning by using pre-trained models on larger, more general datasets and fine-tuning them on the limited hotel review data can also improve performance. Additionally, active learning strategies, where the model iteratively selects the most informative samples for labeling, can make efficient use of limited data resources.
By addressing these challenges with appropriate solutions, sentiment analysis of hotel reviews can become more accurate and reliable, leading to better insights and decision-making for the hospitality industry.
Elevate Your Data with DataHen! 🚀
Struggling with web scraping challenges? Let DataHen's expert solutions streamline your data extraction process. Tailored for small to medium businesses, our services empower data science teams to focus on insights, not data collection hurdles.
Discover How DataHen Can Transform Your Data Journey!
