



TripAdvisor is one of the most recognized platforms for tourism and travel, attracting an average of 490 million unique monthly visitors. It offers reviews, ratings, and detailed information about every tourist-related necessity. In this article, we will learn how to scrape TripAdvisor hotel reviews and gather detailed information.
We'll cover the requirements for scraping TripAdvisor, how to design a web scraper, how to extract and store reviews, and finally, common challenges and their solutions.
Why are hotel reviews important?
Tourism and traveling require thorough preparation to ensure a satisfying experience. A crucial step in this preparation is selecting the right hotel. This is where hotel reviews become invaluable. They provide tourists and travelers with comprehensive information about what a hotel can offer. Hotel reviews help in choosing the best accommodations, while the analysis of these reviews significantly benefits the hospitality industry by enhancing business performance.
How Do Reviews Influence Customer Decision-Making?
When choosing hotels, potential customers often read reviews about prospective places. Positive reviews increase the likelihood of customers selecting a particular hotel by reassuring them of the quality of its service. In contrast, negative reviews help customers avoid potentially bad experiences. Therefore, hotel reviews play a significant role in influencing customer decision-making.
The Impact of Reviews on Hotel Reputation and Business Performance
Hotel reviews significantly impact a hotel's reputation and business performance. Positive reviews enhance a hotel's reputation, attract more bookings, increase occupancy rates, and boost revenue. Conversely, negative reviews can damage a hotel's reputation, reduce bookings, and decrease revenue.
Analyzing hotel reviews is crucial for business performance. Reviews highlight key areas that can help improve a hotel's operations. Businesses need to maintain the positive aspects highlighted in favorable reviews and address the issues raised in negative reviews to enhance their reputation and sustain good business performance. This underscores the importance of hotel review analysis for business success.
How can web scraping help in scraping hotel review data?
Web scraping is a method for automatically extracting data from web pages. This technique allows us to collect specific information, such as restaurant reviews, ratings, and menu details, without manually copying and pasting content. Web scraping enables us to quickly gather large amounts of data and assess its value and relevance to our needs. For instance, by scraping valuable data from TripAdvisor, we can analyze hotel reviews and understand how they influence consumer decisions.
 Shannon Torcato
Shannon Torcato
Main Benefits of using Web Scraping for Collecting Hotel Reviews
Web scraping offers numerous benefits for gathering hotel reviews, with efficiency being a primary advantage. Compared to manual data collection, automated scripts can swiftly compile large volumes of reviews from multiple websites, saving a significant amount of time. This efficiency allows us to handle the steady stream of fresh reviews and maintain the currency and relevance of the data.
Here are the specific benefits of web scraping for collecting hotel reviews:
Efficiency:
- Automated scripts compile large volumes of reviews swiftly.
- Saves significant time compared to manual data collection.
- Maintains the currency and relevance of data by continuously handling fresh reviews.
Comprehensive Data Collection:
- Gather rich data, including review texts, ratings, dates, and reviewer profiles.
- Provides a nuanced understanding of customer feedback.
- Identifies trends, recurring issues, and opportunities for improvement.
Real-Time Updates:
- Regularly running scripts keep track of updated reviews.
- Enables quick responses to client feedback.
- Allows strategy adjustments based on the latest information.
- Ensures continuous data collection to stay competitive in the hospitality sector.
Getting Started with Web Scraping for TripAdvisor Hotel Reviews
Tripadvisor is one of the largest and most popular platforms known for its detailed and authentic reviews, including hotel reviews. By scraping TripAdvisor, we can extract reliable information and vast amounts of data about hotels and public opinions. This data can be used for business performance analysis, helping hotels improve their services by gaining insights from the reviews.
Imagine being able to scrape valuable information such as user reviews, hotel rankings, facilities, and ratings. By analyzing this data, hotels can learn more about their strengths, common complaints, and overall client satisfaction. This knowledge allows them to better align their offerings with customer expectations by tailoring their services and products. Additionally, by understanding the competitive landscape through rankings and reviews, hotels can more effectively strategize their market positioning.
But first, let’s explore the web scraping tools and libraries required to scrape Tripadvisor.
Overview of Web Scraping Tools and Libraries
There are many web scraping tools available, depending on the programming language you prefer:
- BeautifulSoup (Python): This library is used for parsing HTML and XML documents using Python. BeautifulSoup integrates well with other Python libraries such as Requests.
- Cheerio (JavaScript/Node.js): This library is used for parsing HTML and XML documents with a jQuery-like syntax, simplifying the process of selecting and manipulating HTML elements in JavaScript.
- Nokogiri (Ruby): This library is used for parsing HTML and XML documents using Ruby, with 'search' functionality to navigate through documents.
In this guide, we will use Ruby as our programming language, the Nokogiri gem as our primary library, and the fuzzy string match gem to assist with some of our tasks during the TripAdvisor scraping process.
Shannon Torcato
Basic Setup and Requirements
To scrape TripAdvisor, we'll utilize a few essential Ruby packages:
- Nokogiri: A Ruby library used for parsing HTML and XML files. Nokogiri is renowned for its ability to navigate document structures and efficiently extract data, making it ideal for web scraping tasks.
- FuzzyStringMatch: Another Ruby library used for string matching, providing similarity metrics in percentages. This will be utilized in various processes during our scraping operations.
Installation of Required Libraries
Install Nokogiri by running the following command in your terminal:
gem install nokogiriSimilarly, to install FuzzyStringMatch, use:
gem install fuzzy-string-matchFuzzyStringMatch and the Jaro-Winkler Method
FuzzyStringMatch utilizes the Jaro-Winkler Method for string matching. This algorithm measures similarity between two strings using the following components:
- Jaro Distance: Measures similarity based on character matches and transpositions.
- Winkler Adjustment: Enhances the Jaro Distance by assigning more weight to initial matches, making it suitable for tasks where matched strings have common beginnings.
The Jaro-Winkler algorithm assigns higher scores to strings that match from the start and have fewer discrepancies, which is particularly useful when comparing input list strings with current website strings.
Designing the Web Scraper
Our approach to scraping TripAdvisor involves a straightforward search method:
- Browsing the Website: Navigate through TripAdvisor to locate the desired hotel.
- Selecting the Hotel: Choose the specific hotel from the list of search results.
From this search process, we will extract reviews for the selected hotel within a specified time frame. These reviews typically include details such as the hotel's name, city, area, coordinates, and more. To scrape hotel information effectively, we need to match either the hotel's title, city name, or sometimes the area or coordinates.
To facilitate this matching process, we use an input list, often stored in a CSV file. This list contains relevant scopes such as hotel names, city names, areas, coordinates, and more. By comparing this input list with the website's data, we can scrape the necessary hotel information. Using this input list ensures that we focus our scraping efforts only on the specified data.
Before diving into the scraping process, it's essential to understand how to design the web scraper specifically for extracting hotel reviews.
Shannon Torcato
Steps to Create a Web Scraper for Hotel Reviews
Creating a web scraper for hotel reviews is a powerful tool for gathering detailed customer feedback and making data-driven decisions in the hospitality industry. Leveraging Ruby's dynamic and versatile capabilities, developers can automate data extraction from various online review platforms effectively. This guide outlines essential steps to build a robust web scraper in Ruby, ensuring seamless collection and processing of hotel reviews for business insights.
1. Choosing Ruby and Essential Gems:
- Ruby provides flexibility and power for web scraping tasks.
- Utilize gems like 'nokogiri' for HTML parsing and 'fuzzy-string-match' for accurate data matching.
2. Basic Scraper Strategy:
- Perform website searches to locate desired hotels.
- Select specific hotels from search results.
- Retrieve reviews within specified timeframes.
3. Adapting to Website Changes:
- Continuous updates to the scraper maintain reliability amid website updates.
- Recent changes in search results require fetching individual hotel pages for detailed address comparisons, increasing processing complexity.
4. Ensuring Data Accuracy:
- Implement 'fuzzy-string-match' to accurately match hotel details despite varying data presentation on the website.
5. Streamlining Data Retrieval:
- Focus on gathering comprehensive reviews and relevant data from targeted hotel pages.
- Maintain adaptability to handle changes in website layout and information presentation.
By following these steps and adapting to evolving website structures, the web scraper remains effective in extracting valuable hotel review data. This approach ensures businesses can derive actionable insights to improve customer satisfaction and operational strategies in the hospitality sector.
We begin with a CSV formatted input file that includes fields such as the name of the hotel, its address, state, city, country, coordinates, and more. Initially, this file was saved in the input folder. However, over time, we found it more convenient to use a Google Spreadsheet. This approach eliminates the need to update the file in the scraper every time changes are made.
Therefore, the first step is to add a page with a link to the Google Sheet to the queue. This allows for real-time updates and ensures that the scraper always uses the most current information.
pages << {
url: "<google_spreadsheet_url>",
http2: true,
page_type: 'google_spreadsheets',
headers: {
'User-Agent' => "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36"
}
}
The input file, now a Google Spreadsheet, will be included in the page’s content. Using a standard library for working with CSV files, we will read the lines of the file and add the corresponding search pages to the queue. This ensures that each entry in the input file is processed and queued for scraping efficiently.
CSV.parse(content.strip.force_encoding("utf-8"),
encoding: 'utf-8', col_sep: ",", headers: true) do |row|
data = row.to_hash
# Additional processing with `data` variable
end
Inspecting Web Pages to Identify Review Data
To effectively scrape review data, we need to inspect web pages and identify the correct search query format. The format used is '<Hotel name>, <city>, <country>'.
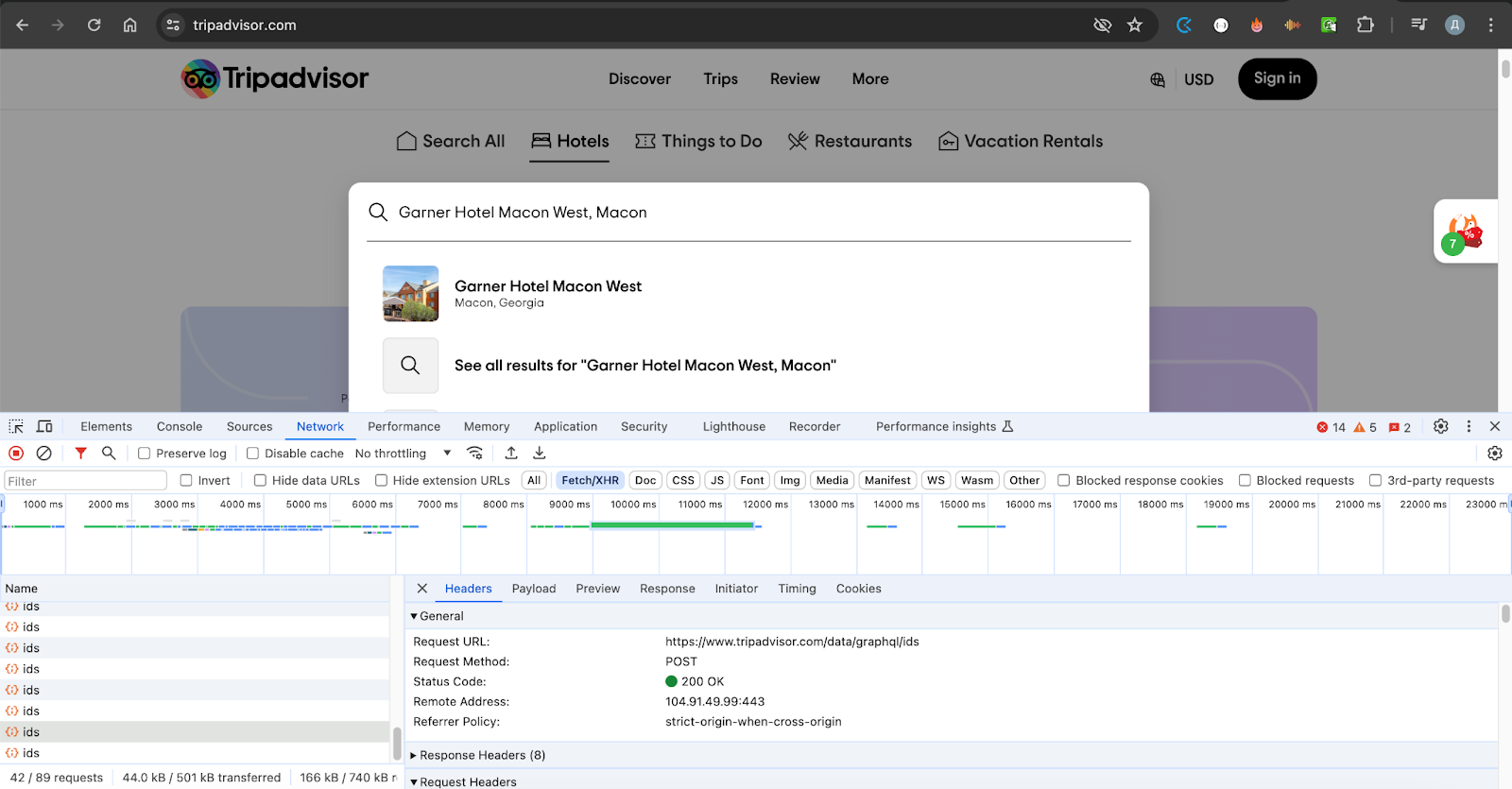
- Identify the Search Query:
- Open the browser console and navigate to the search form on TripAdvisor.
- Begin typing in the site's input field and monitor the requests sent using the network tab in the developer console.
2. Analyze Network Requests:
- Among the network requests, identify the one that returns the desired information, particularly the response that includes location addresses.
- This allows us to compare the results with the search address.
3. Format the Request:
- Copy the identified request and convert it into a format that can be used in the scraper.
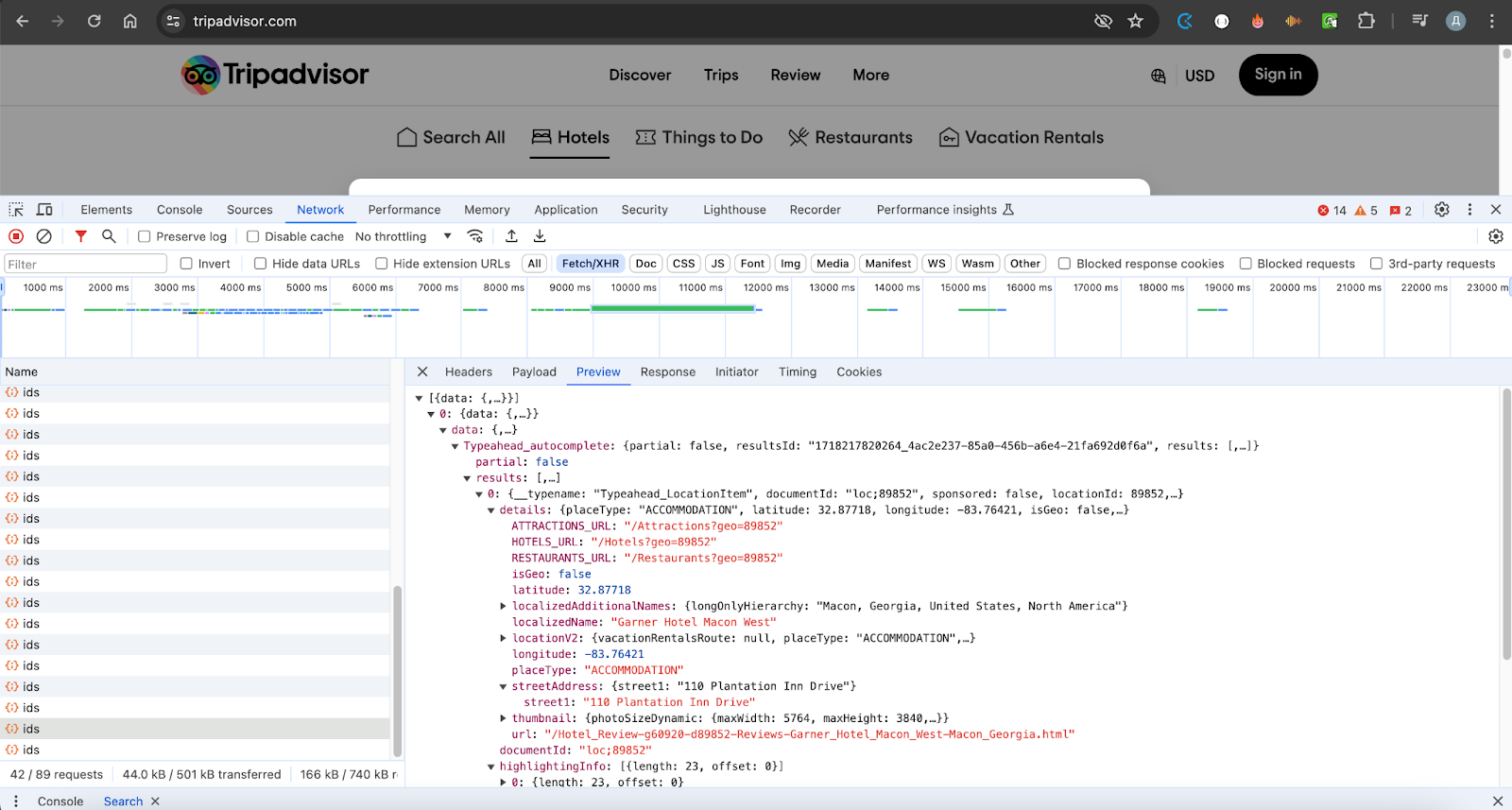
Here’s what the formatted request might look like:
fetch("https://www.tripadvisor.com/data/graphql/ids", {
"headers": {
"accept": "*/*",
"accept-language": "ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7,es;q=0.6",
"content-type": "application/json",
"priority": "u=1, i",
"sec-ch-device-memory": "8",
"sec-ch-ua": "\"Google Chrome\";v=\"125\", \"Chromium\";v=\"125\", \"Not.A/Brand\";v=\"24\"",
"sec-ch-ua-arch": "\"arm\"",
"sec-ch-ua-full-version-list": "\"Google Chrome\";v=\"125.0.6422.142\", \"Chromium\";v=\"125.0.6422.142\", \"Not.A/Brand\";v=\"24.0.0.0\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-model": "\"\"",
"sec-ch-ua-platform": "\"macOS\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "same-origin",
"sec-fetch-site": "same-origin"
},
"referrer": "https://www.tripadvisor.com/",
"referrerPolicy": "strict-origin-when-cross-origin",
"body": "[{\"variables\":{\"request\":{\"query\":\"Garner Hotel Macon West, Macon\",\"limit\":10,\"scope\":\"WORLDWIDE\",\"locale\":\"en-US\",\"scopeGeoId\":1,\"searchCenter\":null,\"types\":[\"LOCATION\",\"QUERY_SUGGESTION\",\"RESCUE_RESULT\"],\"locationTypes\":[\"GEO\",\"AIRPORT\",\"ACCOMMODATION\",\"ATTRACTION\",\"ATTRACTION_PRODUCT\",\"EATERY\",\"NEIGHBORHOOD\",\"AIRLINE\",\"SHOPPING\",\"UNIVERSITY\",\"GENERAL_HOSPITAL\",\"PORT\",\"FERRY\",\"CORPORATION\",\"VACATION_RENTAL\",\"SHIP\",\"CRUISE_LINE\",\"CAR_RENTAL_OFFICE\"],\"userId\":null,\"context\":{\"searchSessionId\":\"000d92b50c2d25b8.ssid\",\"typeaheadId\":\"1718622853077\",\"uiOrigin\":\"homepage_faceted_search_all\",\"routeUid\":\"b318323f-6dc9-4a8a-b0c3-cdb689524126\"},\"enabledFeatures\":[\"articles\"],\"includeRecent\":true}},\"extensions\":{\"preRegisteredQueryId\":\"50ad7bb9462525b2\"}}]",
"method": "POST",
"mode": "cors",
"credentials": "include"
});
By following these steps, we can ensure that our scraper is accurately targeting the correct data on TripAdvisor.
Formulating the Search Request
When inspecting the request body, you’ll notice a line containing the name of the hotel and the city, matching the text entered on the website. Depending on whether the country is specified, the search string will either be '<hotel name>, <city>, <country>' or just '<hotel name>, <city>'.
query = data['LONG_ISO_CTRY_CD'] ? "#{hotel_name}, #{hotel_city}, #{country_config[data['LONG_ISO_CTRY_CD']]}" : "#{hotel_name}, #{hotel_city}"
body = [{"variables":{"request":{"query": query,"limit":10,"scope":"WORLDWIDE","locale":"en-US","scopeGeoId":1, "searchCenter":null,"types":["LOCATION","QUERY_SUGGESTION","RESCUE_RESULT"],"locationTypes":["ACCOMMODATION"],"userId":null,"enabledFeatures":["articles"], "includeRecent":false}},"extensions":{"preRegisteredQueryId":"50ad7bb9462525b2"}}]
Here’s how to convert this information into a format usable by the scraper:
- URL: Use the same URL as on the website.
- Method: POST (refer to HTTP methods).
- Headers: Copy the headers from the browser. Remove any unnecessary ones.
- Body: Copy the request body from the browser. Replace each input line with the corresponding query.
- Page Type: An internal field to help the scraper distinguish between different page types and use the correct parser.
- Vars: Variables passed from one page to another, such as the hotel’s address, city, and name.
pages << {
'url' => "https://www.tripadvisor.com/data/graphql/ids",
'method' => "POST",
'body' => body.to_json,
'http2' => true,
'headers' => {
"accept"=>"*/*",
"accept-language"=>"en-US,en;q=0.9",
"cache-control"=>"no-cache",
"content-type"=>"application/json",
"origin"=>"https://www.tripadvisor.com",
"pragma"=>"no-cache",
"priority"=>"u=1, i",
"referer"=>"https://www.tripadvisor.com/FindRestaurants?geo=294217&establishmentTypes=10591&broadened=false",
"user-agent"=>"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
},
'page_type' => 'graphql_search',
'vars' => {
data: data,
input_hotel_name: hotel_name,
input_hotel_address: hotel_address,
input_hotel_city: hotel_city,
input_hotel_country: hotel_country
}
}
Processing Each Line of the Input File
For each line in the input file, a page is added to the queue. Once the search results are retrieved, the next step is to identify the correct hotel from these results. The search results, typically in JSON format, can be easily parsed to extract necessary data such as hotel names and addresses.
Address Matching Challenges
A potential issue arises when the address format in the input file differs from the format on the website. To address this, we use the 'fuzzy-string-match' gem to calculate approximate string matches.
Using Fuzzy String Matching
- Initial Filtering: Select hotels where the similarity in hotel names is above 0.7. This threshold ensures relevance and comparability.
arow = FuzzyStringMatch::JaroWinkler.create(:pure)
match_title = arow.getDistance(hotel_name, input_hotel_name)
2. Detailed Matching: For each selected hotel, assess the similarity of the address, city, and optionally, country information.
This process helps in accurately identifying and verifying the correct hotels from the input list.
match_address = jarow.getDistance(address, input_hotel_address)
match_city = jarow.getDistance(city, input_hotel_city)
match_country = jarow.getDistance(country, input_hotel_country)
3. Selection Criteria: Aggregate the similarity values and select the hotel with the highest sum.
During the QA stage, instances of incorrect data in the input file, such as inaccuracies in city specifications, are identified and corrected.
Handling the Identified Hotel
Once the correct hotel is identified, initiate the following query:
jarow = FuzzyStringMatch::JaroWinkler.create( :pure )
pages << {
url: <hotel_url>,
page_type: "hotel",
http2: true,
headers: {
"Connection" => "keep-alive",
"Upgrade-Insecure-Requests" => "1",
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
"Accept" => "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding" => "gzip, deflate, br",
"Accept-Language" => "en-US,en;q=0.9",
},
vars: page['vars']
}
Parsing HTML with Nokogiri
We use Nokogiri to parse the HTML, which is a straightforward process thanks to Nokogiri's default methods. This allows us to save the necessary data for each hotel that wasn't available on the search page, including ratings.
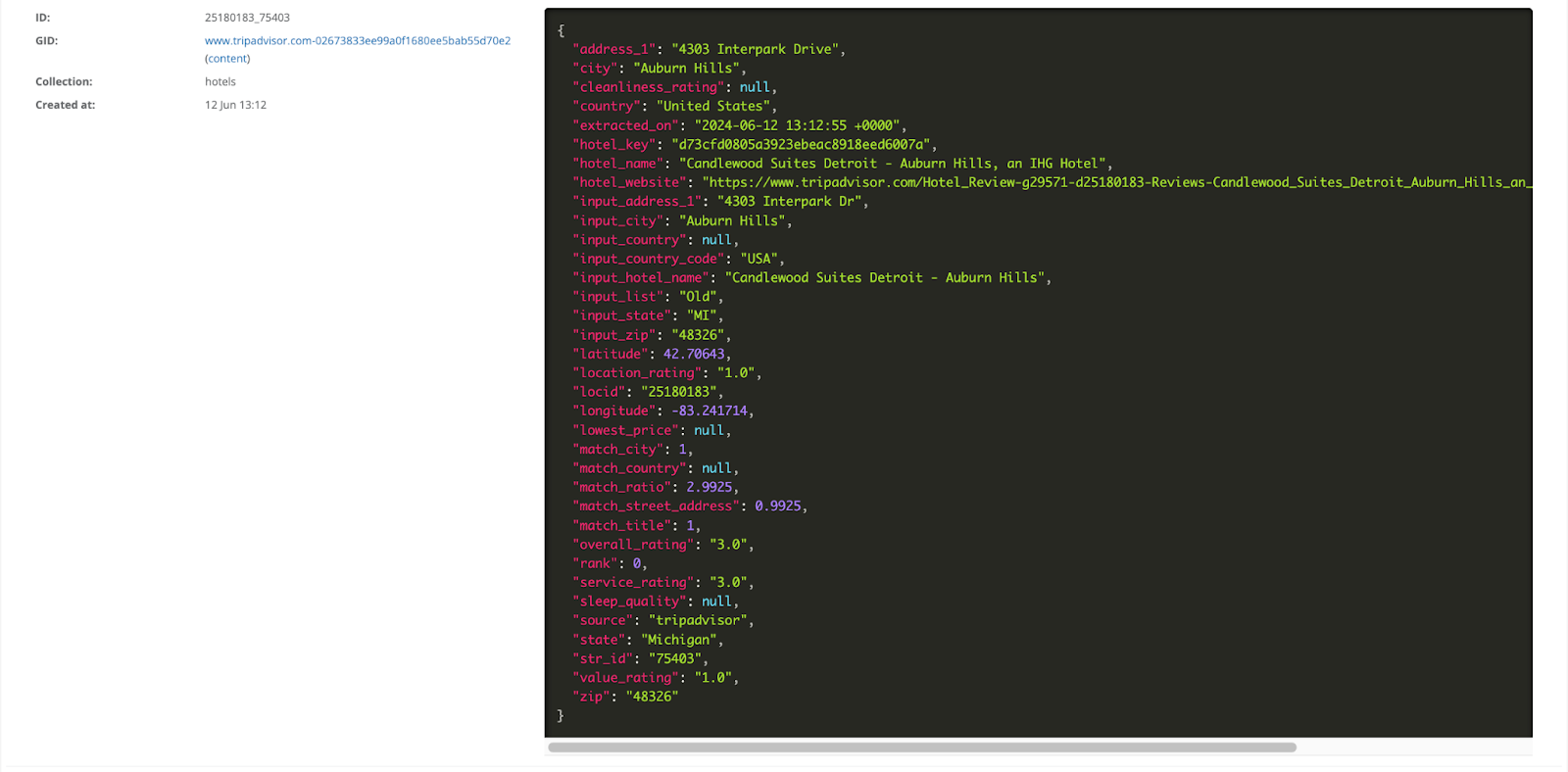
Data Extraction and Review Collection
After saving the essential information, we move on to extracting reviews. These reviews can be easily obtained in JSON format, making our data mining process efficient and effective. Extracting reviews from TripAdvisor provides a rich dataset for hotel review analysis.
Shannon Torcato
Handling Review Sorting Issues
During the review parsing process, we discovered that sorting reviews by date doesn't always work as expected. Occasionally, among the latest reviews, we find a review that was published a year ago. This inconsistency in review sorting requires additional handling to ensure accurate data collection.
Writing Scripts to Extract Data
By writing scripts in Ruby, we can efficiently handle TripAdvisor scraping tasks. Below is a code snippet that demonstrates how to query the website and extract detailed reviews, including titles, user names, review dates, and ratings.
pages << {
'url' => "https://www.tripadvisor.com/data/graphql/ids",
'method' => "POST",
'body' => body.to_json,
'headers' => {
"accept"=>"*/*",
"accept-language"=>"en-US,en;q=0.9",
"cache-control"=>"no-cache",
"content-type"=>"application/json",
"origin"=>"https://www.tripadvisor.com",
"pragma"=>"no-cache",
"priority"=>"u=1, i",
"referer"=>"https://www.tripadvisor.com/FindRestaurants?geo=294217&establishmentTypes=10591&broadened=false",
"user-agent"=>"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
},
'page_type' => 'reviews',
'vars' => {
'hotel' => hotel,
'first' => true,
'locid' => locid,
}
}
Adjustments and Considerations:
- Pagination: This script handles pagination by iterating through review pages until all reviews are retrieved.
- Error Handling: You may want to add error handling to manage potential network issues or changes in the website's structure.
- API Changes: Ensure you review and comply with TripAdvisor's terms of service. Unauthorized scraping can lead to legal issues or IP blocking.
This method of TripAdvisor data extraction enables detailed data mining of hotel reviews, providing valuable insights for comprehensive hotel review analysis.

Information about reviews is presented in a JSON format, conveniently structured, allowing us to easily extract all necessary details such as the title, text, user name, review date, ratings, and more. This structured format is ideal for data mining hotel reviews, as it enables efficient parsing and analysis. The scraper ensures that we capture all relevant information in a consistent and usable format.
As a result, we will add two collections of data to our database: hotels and reviews. You can also export this data into both CSV and JSON formats.
Handling Pagination to Scrape Multiple Pages
For extracting data from HTML pages using Nokogiri, the process is straightforward: locate the required HTML elements and retrieve information. Using Nokogiri, you can parse HTML content and extract data with ease. When working with JSON, the process is even simpler. By parsing the JSON content, you can access the desired fields directly. Here's an example of extracting reviews from a JSON response:
content = '{"reviewListPage":
{"reviews": [{"id": "123", "location": {"locationId": "456"}, "createdDate":
"2023-01-01"}1}}'
json = JSON. parse(content)
json[ "reviewListPage" ]I "reviews" ].each
do | review|
review_id = "#{review['id']}_#
{review['location']['locationId']}"
review_date = review['createdDate']
puts "Review ID: #{review_id}" puts "Review Date: #{review_date}"
end
In both cases, the key steps are to parse the content (HTML or JSON) and then access the required elements or fields to extract the information.
Dealing with Dynamic Content and JavaScript Rendering
When scraping TripAdvisor, it is important to check what kind of content we currently deal with. We can recognize that we are dealing with static content rather than dynamic content. Static content means the information we need is embedded into the HTML itself, while dynamic content, just by its name, dynamically updates the content. Dynamic content will be loaded after the initial HTML page is loaded, which brings us to a problem, that is JavaScript rendering.
JavaScript rendering is basically the main process of loading dynamic content. The content is generated by JavaScript rather than embedded into the HTML page itself, which makes additional requests to fetch the data. Fortunately, this wasn’t the case for scraping TripAdvisor, so everything would be fine with these code snippets and guides, step-by-step.
Shannon Torcato
Common Challenges in Web Scraping and the Solutions We Offer
Scraping TripAdvisor can be challenging at times. Here are a few common challenges and solutions for scraping TripAdvisor effectively:
Numbers of Review Reduction: There are limits on the number of reviews that can be retrieved from TripAdvisor, which have changed from 400 reviews per request to just 20 reviews per request. This change necessitates loading more review pages to gather the same amount of data, increasing the duration of the process.
To address this problem, we load review pages until all reviews before our specified date are obtained. This process involves checking each page and stopping when we have scraped the relevant reviews.
Basic Maintenance of Website: Minor changes in the website, such as updates in the HTML template or changes in headers, can create issues. These problems generally do not present significant challenges but require us to identify, make necessary changes, test, deploy, and monitor the scraper regularly.
Missing Addresses from Search Results: This issue required us to reconsider our approach to scrape the necessary information and reviews. Missing addresses from search results often need to be checked against the input list, which includes a quality check of the data and adding the correct information to the input list.
How DataHen Can Help
At DataHen, we specialize in overcoming the challenges associated with web scraping. Our expert team can help you:
- Implement robust scraping solutions that handle changes in website structure.
- Optimize scraping processes to handle review reduction limits and ensure efficient data extraction.
- Maintain and update scrapers regularly to adapt to any updates or changes on TripAdvisor.
- Integrate advanced techniques to manage anti-scraping measures, including rate limiting, User-Agent rotation, and CAPTCHA handling.
Let DataHen be your partner in extracting valuable insights from TripAdvisor reviews. With our expertise, you can focus on analyzing the data to improve your business strategy while we take care of the complexities of web scraping. Contact us today to learn more about how we can assist you in achieving your data extraction goals.
